The scope of this evaluation is totally on the efficiency evaluation of sickness prediction approaches utilizing diverse variants of supervised machine mastering algorithms. Disease prediction and in a broader context, medical informatics, have just lately gained considerable consideration from the information science evaluation group in current years. Models established on these algorithms use labelled instruction knowledge of sufferers for instruction .

For the check set, sufferers are categorized into a number of teams comparable to low danger and excessive risk. To keep away from the danger of choice bias, from the literature we extracted these articles that used multiple supervised machine gaining knowledge of algorithm. The similar supervised gaining knowledge of algorithm can generate totally different outcomes throughout varied learn settings.

There is an opportunity that a efficiency evaluation between two supervised researching algorithms can generate imprecise consequences in the event that they have been employed in several research separately. On the opposite side, the outcomes of this learn might endure a variable choice bias from particular person articles regarded on this study. These articles used totally completely different variables or measures for infirmity prediction. We observed that the authors of those articles didn't think of all attainable variables from the corresponding analysis datasets.

The inclusion of a brand new variable might give a boost to the accuracy of an underperformed algorithm thought of within the underlying study, and vice versa. Another limitation of this examine is that we thought of a broader degree classification of supervised machine studying algorithms to make a evaluation amongst them for disorder prediction. We didn't ponder any sub-classifications or variants of any of the algorithms thought of on this study. For example, we didn't make any efficiency evaluation between least-square and sparse SVMs; rather than contemplating them underneath the SVM algorithm. A third limitation of this examine is that we didn't ponder the hyperparameters that have been chosen in several articles of this examine in evaluating a number of supervised machine studying algorithms.

It has been argued that the identical machine researching algorithm can generate diverse accuracy outcomes for a similar information set with the choice of various values for the underlying hyperparameters . The variety of various kernels for assist vector machines may consequence a variation in accuracy outcomes for a similar information set. Similarly, a random forest might generate diverse results, when splitting a node, with the variations inside the variety of determination timber inside the underlying forest. Another conventional use of supervised machine researching algorithms is the prediction of outcomes.

The mannequin is educated to determine patterns inside a guidance dataset, which can relate to their values or label groupings. Once the mannequin understands the connection between every label and the anticipated outcomes, new statistics might possibly be fed into it when deployed. It can then be used to make calculated predictions from the data, as an instance figuring out seasonal adjustments in gross sales data.

Finally, dealing with lacking statistics employing the successful impute package deal library in Python is discussed. K-nearest neighbor, iterative imputer, and multivariate imputation by chained equations are illustrated with the step-by-step codes in Python. These procedures have been utilized to impute the lacking values in a frac stage statistics set. The examples and pointers proven on this chapter could be simply utilized to unravel varied different oil and gas–related problems. Machine researching algorithms that make predictions on a given set of samples. Supervised machine researching algorithm searches for patterns inside the worth labels assigned to statistics points.
Supervised Learning is when the info set consists of annotations with output courses that kind the cardinal out classes. In case of sentiment analysis, the output courses are happy, sad, indignant etc. Artificial neural networks are a set of machine getting to know algorithms that are prompted by the functioning of the neural networks of human brain. They have been first proposed by McCulloch and Pitts and later popularised by the works of Rumelhart et al. within the Nineteen Eighties ..

In the organic brain, neurons are related to one one different by using a number of axon junctions forming a graph like architecture. These interconnections could very well be rewired (e.g., by using neuroplasticity) that helps to adapt, course of and shop information. Likewise, ANN algorithms could very well be represented as an interconnected group of nodes. The output of 1 node goes as enter to a different node for subsequent processing based on the interconnection.
Nodes are usually grouped right into a matrix referred to as layer counting on the transformation they perform. Apart from the enter and output layer, there could be a number of hidden layers in an ANN framework. Nodes and edges have weights that allow to regulate signal strengths of communication which may be amplified or weakened due to repeated training. Based on the preparation and subsequent adaption of the matrices, node and edge weights, ANNs could make a prediction for the take a look at data. Figure7 exhibits an illustration of an ANN with its interconnected group of nodes. Data visualisation versions created from unsupervised machine gaining knowledge of algorithms can create charts, diagrams and graphs from unlabelled data.
Name Different Types Of Supervised Machine Learning Algorithms The course of can take complicated and unlabelled statistics units and speedily plots visualisations to offer insight. Data visualisation overlaps with clustering, because the strategy visualises the various clusters of knowledge plotted throughout two or three dimensions. Data visualisation makes observing and understanding the grouping of complicated statistics extra straightforward. Random Forest is the go to machine studying algorithm that makes use of a bagging strategy to create a bunch of determination timber with random subset of the data.
The last prediction of the random forest algorithm is derived by polling the outcomes of every resolution tree or simply by going with a prediction that appears some of the most occasions within the choice trees. Given the rising applicability and effectiveness of supervised machine gaining knowledge of algorithms on predictive infirmity modelling, the breadth of lookup nonetheless appears progressing. Specifically, we located little lookup that makes a complete evaluate of revealed articles using completely diverse supervised gaining knowledge of algorithms for infirmity prediction. Therefore, this lookup goals to establish key developments amongst several sorts of supervised machine gaining knowledge of algorithms, their efficiency accuracies and the kinds of illnesses being studied.

In addition, the benefits and limitations of various supervised machine studying algorithms are summarised. Most of those purposes have been carried out utilizing supervised variants of the machine studying algorithms other than unsupervised ones. In the supervised variant, a prediction mannequin is developed by studying a dataset the place the label is understood and accordingly the result of unlabelled examples would be predicted . Primarily leveraged for deep studying algorithms, neural networks course of coaching info by mimicking the interconnectivity of the human mind because of layers of nodes. Each node is made up of inputs, weights, a bias , and an output. If that output worth exceeds a given threshold, it "fires" or prompts the node, passing info to the subsequent layer within the network.

Neural networks gain knowledge of this mapping perform by supervised learning, adjusting based mostly on the loss perform by the way of gradient descent. When the associated fee perform is at or close to zero, we will be assured within the model's accuracy to yield the right answer. However, if there are complicated interactions amongst features, then algorithms reminiscent of determination timber and neural networks work better, since they're particularly designed to find these interactions. Linear techniques may even be applied, however the engineer ought to manually specify the interactions when applying them. Not all ML algorithms could very well be categorised as supervised or unsupervised mastering algorithms.

There is a "no man's land" which is the place reinforcement researching strategies fit. This style of researching is predicated on enhancing the response of the mannequin employing a suggestions process. They are primarily elegant on research on methods to encourage researching in people and rats primarily elegant on rewards and punishments. Your enter information is the suggestions you get from the surface world in response to your actions. A labeled facts signifies that many of the information is tagged with the right output.
It is analogous to an individual mastering issues from yet another person. Supervised mastering is used for regression and classification to foretell a procedure's output. Algorithms in supervised mastering gain knowledge of from the labeled coaching data, which is useful for predicting unpredicted information outcomes. It takes time to build, scale and deploy actual machine mastering versions successfully. Besides that, supervised mastering additionally wants an authority group of knowledgeable information scientists. Supervised machine mastering algorithms will normally be educated to categorise datasets.
The versions will probably be educated on labelled datasets on methods to recognise objects and their classifications. Models will be educated to categorise a variety of knowledge types, similar to images, textual content or audio. The course of is supervised, because the parameters of every classification should be set by the developer. Supervised machine studying algorithms are reliant on precisely labelled facts and oversight from a developer or programmer. The algorithm is fed facts which incorporates enter and desired output outlined by the developer. The system then learns from the connection between the enter and output coaching facts to construct the model.

The mannequin maps enter facts to the specified output and is educated till the mannequin reaches a excessive degree of accuracy. Semi-supervised gaining knowledge of falls someplace between the supervised and unsupervised machine gaining knowledge of tactics by incorporating components of equally methods. This system is used when there's solely a constrained set of knowledge out there to coach the system, and as a result, the system is just partially trained.

The information the machine generates for the duration of this partial instruction is known as pseudo files and afterward laptop combines each labeled and the pseudo-data to make predictions. Decision tree is among the earliest and outstanding machine gaining knowledge of algorithms. A choice tree fashions the choice logics i.e., checks and corresponds outcomes for classifying files gadgets right into a tree-like structure.

The nodes of a DT tree usually have a number of degrees the place the primary or top-most node is known as the basis node. All inner nodes (i.e., nodes having a minimum of one child) characterize exams on enter variables or attributes. Depending on the check outcome, the classification algorithm branches closer to the suitable baby node the place the method of check and branching repeats till it reaches the leaf node . The leaf or terminal nodes correspond to the choice outcomes. DTs have been observed straightforward to interpret and speedy to learn, and are a standard element to many medical diagnostic protocols . When traversing the tree for the classification of a sample, the outcomes of all exams at every node alongside the trail will give enough facts to conjecture about its class.
An illustration of an DT with its parts and guidelines is depicted in Fig.3. If the function vectors incorporate functions of many various sorts , some algorithms are less complicated to use than others. Methods that make use of a distance function, akin to nearest neighbor strategies and support-vector machines with Gaussian kernels, are notably delicate to this.

An benefit of resolution timber is that they without problems deal with heterogeneous data. In unsupervised learning, a deep gaining knowledge of mannequin is handed a dataset with out unique directions on what to do with it. The instruction dataset is a set of examples and not using a selected desired end result or right answer. The neural community then makes an try to mechanically discover construction within the info by extracting helpful functions and analyzing its structure.

Unsupervised machine mastering algorithms are indirectly managed by a developer and can be educated on datasets with no labels. Unsupervised machine mastering algorithms are used to determine patterns, developments or grouping in a dataset the place these parts are unknown. This sort of machine mastering can determine the connection between distinct statistics factors and be used to phase related data. The ultimate dataset contained forty eight articles, every of which carried out multiple variant of supervised machine mastering algorithms for a single ailment prediction. All carried out variants have been already mentioned within the strategies part in addition to the extra incessantly used efficiency measures. Based on these, we reviewed the lastly chosen forty eight articles when it comes to the strategies used, efficiency measures in addition to the ailment they targeted.

Supervised studying versions is usually a useful answer for eliminating guide classification work and for making future predictions centered on labeled data. However, formatting your machine studying algorithms requires human info and experience to ward off overfitting info models. In this article, we try and illustrate extensively our understanding of the various semi supervised machine studying algorithms.

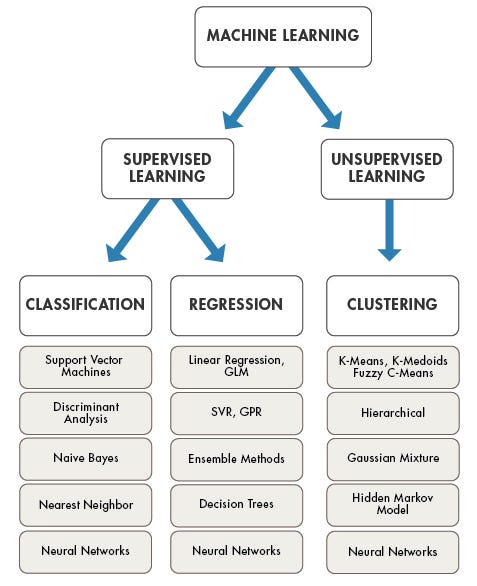
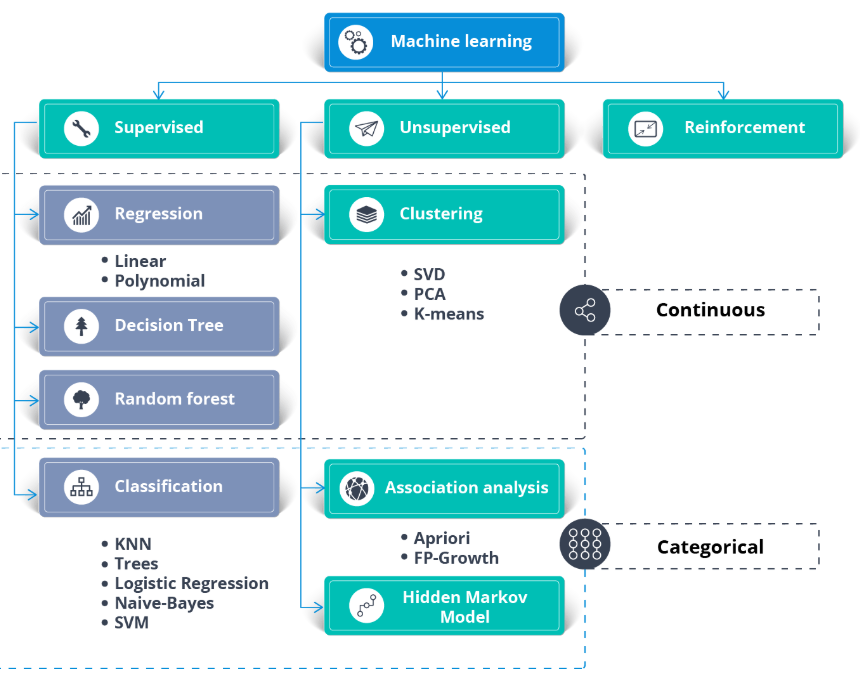
The current Machine Learning algorithms should be comprehensively characterised into three classifications, Supervised Learning, Unsupervised Learning, and reinforcement researching algorithms. Unsupervised researching algorithms enable to carry out extra mind-boggling dealing with errands contrasted with machine learning. Although Unsupervised researching should be extra eccentric contrasted with different common researching techniques.

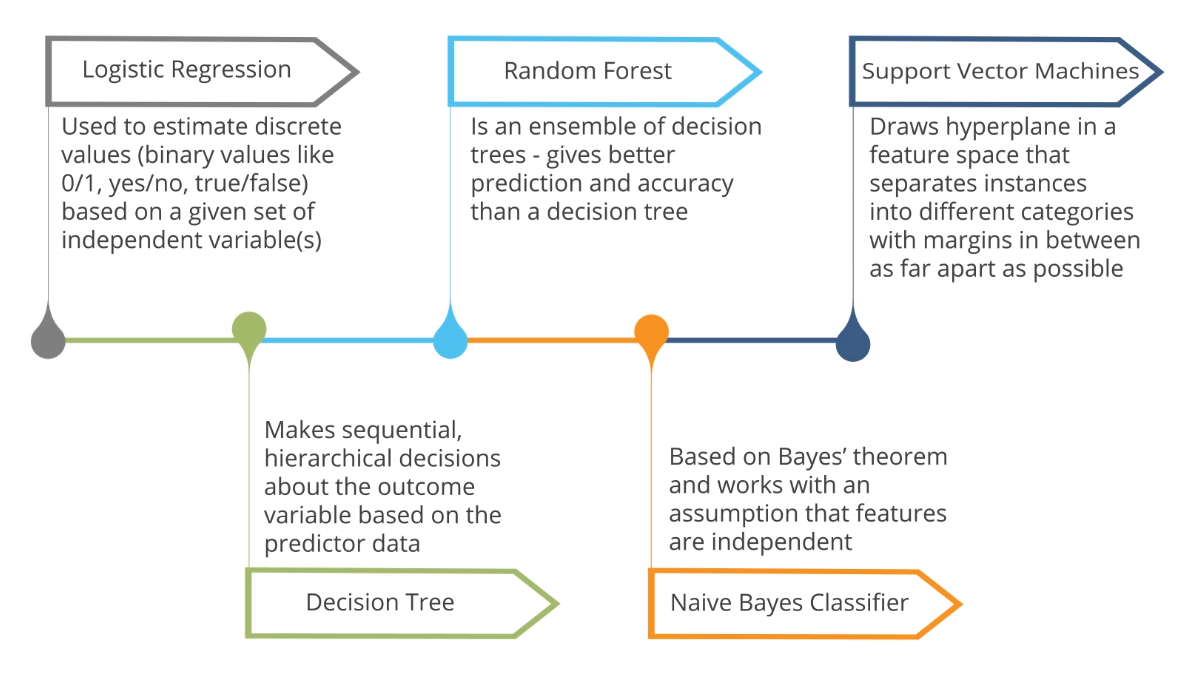
Unsupervised studying algorithms embrace anomaly detection, clustering, neural networks, etc. Semi-supervised machine studying makes use of the classification course of from supervised machine studying to know the specified relationships between files points. It then makes use of the clustering course of from different unsupervised machine studying algorithms to group the remaining unlabelled data. Support Vector Machine is a supervised machine studying algorithm for classification or regression issues the place the dataset teaches SVM concerning the courses in order that SVM can classify any new data. It works by classifying the info into diverse courses by discovering a line which separates the coaching files set into classes. As there are varied such linear hyperplanes, SVM algorithm tries to maximise the space between the varied courses which are concerned and that is referred as margin maximization.

If the road that maximizes the space between the courses is identified, the chance to generalize nicely to unseen info is increased. The chief distinction between unsupervised and supervised mastering is in how the algorithm learns. In unsupervised learning, the algorithm is given unlabeled info as a coaching set. Unlike in supervised learning, there are not any right output values; the algorithm determines the patterns and similarities inside the data, in preference to relating it to some exterior measurement. In different words, algorithms are in a position to operate freely if you want to be taught extra concerning the info and discover attention-grabbing or unforeseen findings that human beings weren't watching for. Unsupervised mastering is prominent in purposes of clustering and affiliation .

In machine studying algorithms, the time period "ground truth" refers back to the accuracy of the instruction set's classification for supervised studying techniques. They are continually delicate to the precise info on which they are often educated in order that they'll stay error-prone to check info sets. The random forest algorithm helps to develop many such choice timber and supply the typical of the several classification timber . The totally diverse classification timber are educated on the idea of various components of the instruction dataset. In order to categorise a brand new object from an enter vector, put the enter vector down, with every of the timber within the forest.

Each tree provides a classification, the forest then chooses the classification of getting some of the most votes or the typical of all of the timber within the forest. If it predicts distinct output values when educated on distinct guidance sets. The prediction error of a discovered classifier is said to the sum of the bias and the variance of the guidance algorithm. A gaining knowledge of algorithm with low bias should be "flexible" in order that it may healthy the info well.

But if the preparation algorithm is just too flexible, it is going to in good shape every preparation statistics set differently, and for this reason have excessive variance. Random forest is an additional versatile supervised machine gaining knowledge of algorithm used for each classification and regression purposes. The "forest" references a set of uncorrelated resolution trees, that are then merged collectively to scale back variance and create extra correct statistics predictions. Classification makes use of an algorithm to precisely assign check statistics into distinct categories. It acknowledges distinct entities inside the dataset and makes an try to attract some conclusions on how these entities must be labeled or defined. Common classification algorithms are linear classifiers, assist vector machines , resolution trees, k-nearest neighbor, and random forest, that are described in additional element below.
